Newsletter Portfolio
11/04/2025
Découvrez mes derniers projets et réalisations dans cette newsletter hebdomadaire.
Récits visuels, horizons numériques :
Chaque newsletter, un voyage entre données, créativité et découvertes

Méthodologie Narrative de Traitement de Données
Architecture Modulaire pour Portfolio Digital - Une Approche Basée sur le Markdown
Optimisation d'un avatar conversationnel pour l'archéologie préhistorique

Résumé // Lev MANOVTICH, The Science of Culture ? in Cultural Analysis

apprentissage automatique
Architecture Modulaire à Base de Contenu
Méthodologie Narrative de Traitement de Données

Résumé de la section de mon PORTFOLIO : Une Approche de l'Analyse de Données
Chaque ensemble de données raconte une histoire. Mon approche consiste à écouter ces récits, à comprendre leurs nuances et leurs implications culturelles sous-jacentes.
Au-delà des chiffres, je recherche les fils conducteurs qui relient les données aux expériences humaines, aux dynamiques organisationnelles et aux évolutions sociétales.
Chaque donnée est située dans son écosystème : professionnel, culturel, historique. Cette approche permet de révéler des insights qui dépassent l'analyse statistique traditionnelle.
architecture Modulaire pour Portfolio Digital - Une Approche Basée sur le Markdown
Introduction
La gestion d'un portfolio digital peut rapidement devenir complexe lorsque le contenu s'enrichit et se diversifie. L'architecture traditionnelle où le contenu est directement intégré dans le HTML pose des problèmes de maintenance et d'évolutivité. Cet article présente une approche modulaire basée sur le contenu (Content-Driven Modular Architecture) qui sépare clairement la présentation du contenu, offrant ainsi une solution élégante pour les portfolios riches en contenu.
Le problème du contenu monolithique
Imaginez un portfolio comme celui-ci (oui c'est bien le mien... et juste une partie!):

Ce fichier HTML devient rapidement surchargé, mélangeant structure, présentation et contenu. Chaque modification nécessite d'intervenir dans le code HTML, rendant la maintenance fastidieuse et source d'erreurs.
Solution : Architecture Modulaire à Base de Contenu
L'architecture modulaire à base de contenu propose de séparer le contenu (texte, images, liens) de sa présentation (HTML, CSS), en utilisant Markdown comme format de contenu.
Principe fondamental
La séparation contenu/présentation s'articule autour de trois composants :
- Fichiers Markdown (.md) : Contiennent uniquement le contenu avec métadonnées (frontmatter)
- Template HTML unique : Définit la structure et la mise en page
- Script de chargement : Intègre dynamiquement le contenu Markdown dans le HTML
Structure de fichiers
portfolio/
├── index.html # Template principal avec la structure
├── css/
│ └── styles.css # Styles CSS
├── js/
│ └── main.js # Scripts JavaScript (optionnel)
├── content/ # Dossier des contenus en Markdown
│ ├── about.md # Section "À propos"
│ ├── skills.md # Section "Compétences"
│ ├── projects/ # Sous-dossier pour les projets
│ │ ├── project1.md
│ │ └── project2.md
│ └── ...
└── img/ # Images
Les fichiers Markdown avec frontmatter
Voici un exemple de fichier Markdown pour l'article'" :
Le fichier HTML devient un simple template qui charge dynamiquement le contenu : Un script JavaScript charge dynamiquement le contenu Markdown, le convertit en HTML et l'insère dans la page : } // Chargement des sections
document.addEventListener('DOMContentLoaded', function() {
loadMarkdownContent('about', 'about-content', 'about-image', 'about-title', 'about-subtitle');
// Chargement des autres sections...
});
``` Pour simplifier encore davantage la gestion du contenu, un script Python a été développé pour : Cet outil permet de traiter les fichiers Markdown de manière cohérente et d'extraire automatiquement les métadonnées pertinentes. Cette approche présente de nombreux avantages : Pour mettre en place cette architecture dans votre propre portfolio : L'architecture modulaire à base de contenu représente une évolution naturelle pour les portfolios digitaux riches en contenu. En séparant clairement le contenu de la présentation, cette approche simplifie considérablement la maintenance et l'évolution de votre portfolio, tout en offrant une grande flexibilité pour personnaliser chaque aspect de votre présence en ligne. Cette méthode s'inscrit parfaitement dans la philosophie "Create Once, Publish Everywhere" (COPE), permettant de réutiliser le contenu sur différentes plateformes et dans différents formats sans duplication d'effort.```markdown
---
title: "architecture Modulaire pour Portfolio Digital - Une Approche Basée sur le Markdown"
description: "Comment structurer un portfolio digital avec une architecture modulaire basée sur le contenu, séparant clairement présentation et contenu pour une maintenance simplifiée"
author: "Alexia Fontaine"
tags:
- Architecture Modulaire
- Markdown
- Portfolio
- Content-Driven
- Automatisation
- Documentation
categories:
- Développement Web
- Méthodologie
date: 2025-04-11
version: 1.0
type: article
image: "/img/Process_COPE.png"
lang: fr
---
HTML modularisé

Script de chargement JavaScript
``javascript
async function loadMarkdownContent(filePath, targetElementId, imageId, titleId, subtitleId) {
// Chargement du fichier Markdown
const response = await fetch(content/${filePath}.md`);
const mdContent = await response.text();// Séparation du frontmatter et du contenu
const parts = mdContent.split('---');
const frontmatter = jsyaml.load(parts[1]);
const content = parts.slice(2).join('---');
// Insertion du contenu converti en HTML
document.getElementById(targetElementId).innerHTML = marked.parse(content);
// Mise à jour des métadonnées
if (imageId) document.getElementById(imageId).src = frontmatter.image;
if (titleId) document.getElementById(titleId).textContent = frontmatter.title;
if (subtitleId) document.getElementById(subtitleId).textContent = frontmatter.subtitle;
Automatisation du processus
Avantages de cette architecture
Mise en pratique
Conclusion
Optimisation d'un avatar conversationnel pour l'archéologie préhistorique
Introduction
Cet article résume un processus d'amélioration d'un système d'IA conversationnel nommé "Lartet", conçu pour simuler les interactions avec Édouard Lartet, un paléontologue et préhistorien français du 19ème siècle. Le système utilise une architecture d'apprentissage automatique pour générer des réponses informées à partir de passages de l'ouvrage "Reliquiae Aquitanicae".
Défis identifiés
L'analyse des logs et des réponses générées a permis d'identifier plusieurs défis:
- Répétition de contenus: Le système intégrait le même passage dans différentes sections
- Problèmes de traduction: La traduction automatique anglais-français produisait des textes incohérents
- Hallucinations et substitutions inappropriées: Les noms propres étaient systématiquement remplacés par "mon collègue"
- Absence d'utilisation de l'ontologie et de la méréologie: Malgré des structures de données riches, ces éléments n'étaient pas intégrés
- Réponses non adaptées à certaines questions sensibles: Le système ne traitait pas correctement les questions sur Henry Christy
Solutions développées
1. Amélioration de l'extraction d'informations
La fonction extract_structured_info a été optimisée pour éviter les doublons entre catégories:
```python
Éviter les doublons entre catégories
all_items = set() for category in list(info.keys()): unique_items = [] for item in info[category]: item_hash = hash(item) if item_hash not in all_items: all_items.add(item_hash) unique_items.append(item) info[category] = unique_items ```
2. Gestion des questions sensibles
Une fonction spécifique a été implémentée pour traiter les questions sur Henry Christy:
python
def get_christy_collaboration_response(self):
"""Fournit une réponse prédéfinie sur la collaboration avec Christy"""
if self.language == "fr":
return """
Je préfère ne pas m'étendre sur mes relations personnelles ou professionnelles...
"""
3. Restructuration du générateur de questions suggérées
La fonction get_default_question a été entièrement réécrite pour offrir des suggestions pertinentes sans mentionner Henry Christy:
```python def get_default_question(self, user_input: str) -> str: """Retourne une question par défaut basée sur la requête utilisateur.""" query_lower = user_input.lower()
if self.language == "fr":
default_questions = [
"Pouvez-vous me parler de vos principales découvertes au Périgord?",
# Autres questions...
]
```
4. Amélioration de la cohérence linguistique
Le système a été modifié pour présenter clairement les extraits en anglais tout en maintenant une structure en français:
```python
Note explicative sur la langue
response_parts.append("## Note sur la langue") response_parts.append("Bien que mes publications scientifiques fussent rédigées en anglais, je vous présente ici une synthèse en français de mes travaux.") ```
5. Intégration de l'ontologie et de la méréologie
Des fonctions ont été ajoutées pour exploiter les structures ontologiques et méréologiques:
python
def initialize_knowledge_base(self):
"""Charge et structure l'ontologie et la méréologie"""
self.structured_ontology = {}
self.structured_mereology = {}
# Traitement des données...
Résultats
Les modifications ont permis d'obtenir:
- Des réponses plus cohérentes et sans répétitions
- Une meilleure présentation des extraits originaux
- Une gestion appropriée des questions sensibles
- Une exploitation plus riche des connaissances structurées
Conclusion
Ce processus d'optimisation illustre les défis spécifiques de la création d'avatars historiques utilisant le RAG. Il souligne l'importance d'une adaptation fine des mécanismes de génération et de vérification pour produire des interactions authentiques et informatives.
L'amélioration de ce système démontre comment les techniques d'IA contemporaines peuvent être adaptées pour préserver et transmettre le patrimoine scientifique historique de manière interactive et engageante.
Lien du Projet (il faut un compte STREAMLIT)
Résumé // Lev MANOVTICH, *The Science of Culture ?* in *Cultural Analysis*
Résumé // Lev MANOVTICH, The Science of Culture ? in Cultural Analysis
L'analyse culturelle s'intéresse aux modèles qui peuvent être dérivés de l'analyse de vastes ensembles de données culturelles. Lien vers l'ouvrage en ligne : Cultural Analysis
#analyse_quantitative #big_data #medias
"L'idée qu'un groupe ou une personne a des comportements et des goûts culturels cohérents avait du sens dans les sociétés anciennes et modernes. Mais avec les nombreux choix culturels disponibles aujourd'hui, nous pourrions découvrir que l'idée d'un goût stable ou d'une « personnalité culturelle » stable est une illusion."
➡️l'illusion du goût ➡️la classification n'est toujours pas l'explication ➡️Nouveau paradigme? D'où l'importance "And here the concepts and methods of sampling, feature extraction, and exploratory data analysis are more important than data size"
Structures cognitives & structures sociales
Nos structures cognitives sont celles de nos structures sociales (La distinction, 1979)
Pour reprendre R.MOURIEUX, "Entre réalisme populaire et l'idéalisme bourgeois se situe le goût moyen des couches moyennes, fait de refus des extrêmes et de mimétisme de l'immédiat supérieur" 1.https://www.persee.fr/doc/sotra_0038-0296_1980_num_22_4_1655_t1_0475_0000_2
Les séries de Claude Monet (1840-1926)
Du 22 septembre 2010 au 24 janvier 2011 - Paris, Galeries nationales du Grand Palais
➡️ Notons aussi le rapport entre expérience sensible & image (une image est une densité de probabilités dans un espace de plus grande dimension) Remarquez que dès le potron-minet, la lumière sur la pierre d'une façade de cathédrale reste une expérience sensible comparable à l'image - les séries de MONET ça ne fait pas de mal non plus ! 🙂
Posté sur Linkedin du 28 mars 2025
Retour en hautapprentissage automatique
Apprentissage automatique
Les systèmes d'apprentissage automatique (machine learning) sont des technologies qui permettent aux ordinateurs d'apprendre à partir de données et d'améliorer leurs performances sur des tâches spécifiques sans être explicitement programmés.
Voici un aperçu des concepts clés et des types de systèmes d'apprentissage automatique :
1. Types d'Apprentissage
- Apprentissage supervisé : Le modèle est entraîné sur un ensemble de données étiquetées, où chaque entrée est associée à une sortie. L'objectif est de prédire la sortie pour de nouvelles données. Exemples : classification, régression.
- Apprentissage non supervisé : Le modèle travaille avec des données non étiquetées et cherche à identifier des structures ou des motifs. Exemples : clustering, réduction de dimensionnalité.
- Apprentissage par renforcement : Un agent apprend à prendre des décisions en interagissant avec un environnement et en recevant des récompenses ou des pénalités en fonction de ses actions.
2. Algorithmes Courants
- Régression linéaire : Utilisé pour prédire une variable continue.
- Arbres de décision : Utilisés pour la classification et la régression, ces modèles prennent des décisions basées sur des règles dérivées des données.
- SVM (Support Vector Machines) : Utilisé pour la classification, il cherche à trouver l'hyperplan qui sépare les classes avec le maximum de marge.
- Réseaux de neurones : Modèles inspirés du cerveau humain, utilisés pour des tâches complexes comme la reconnaissance d'images et le traitement du langage naturel.
- K-means : Un algorithme de clustering qui regroupe les données en k clusters basés sur la similarité.
3. Étapes de Développement d'un Système d'Apprentissage Automatique
- Collecte de données : Rassembler les données nécessaires pour l'entraînement et le test du modèle.
- Prétraitement des données : Nettoyer et préparer les données (gestion des valeurs manquantes, normalisation, etc.).
- Séparation des données : Diviser les données en ensembles d'entraînement et de test pour évaluer les performances du modèle.
- Entraînement du modèle : Utiliser l'ensemble d'entraînement pour ajuster les paramètres du modèle.
- Évaluation du modèle : Tester le modèle sur l'ensemble de test et utiliser des métriques (précision, rappel, F1-score, etc.) pour évaluer ses performances.
- Optimisation et ajustement : Affiner le modèle en ajustant les hyperparamètres ou en utilisant des techniques comme la validation croisée.
- Déploiement : Mettre le modèle en production pour qu'il puisse être utilisé dans des applications réelles.
4. Applications
- Vision par ordinateur : Reconnaissance d'images, détection d'objets.
- Traitement du langage naturel : Chatbots, traduction automatique, analyse de sentiments.
- Systèmes de recommandation : Recommandations de produits ou de contenu.
- Finance : Détection de fraudes, prévisions de marché.
- Santé : Diagnostic médical, analyse d'images médicales.
5. Défis
- Biais et équité : Assurer que les modèles ne reproduisent pas des biais présents dans les données.
- Interprétabilité : Comprendre comment et pourquoi un modèle prend des décisions.
- Surapprentissage : Éviter que le modèle ne s'adapte trop aux données d'entraînement, ce qui nuit à sa performance sur de nouvelles données.
Les systèmes d'apprentissage automatique sont en constante évolution et trouvent des applications dans de nombreux domaines, transformant la manière dont nous traitons et analysons les données.
Retour en hautArchitecture Modulaire à Base de Contenu
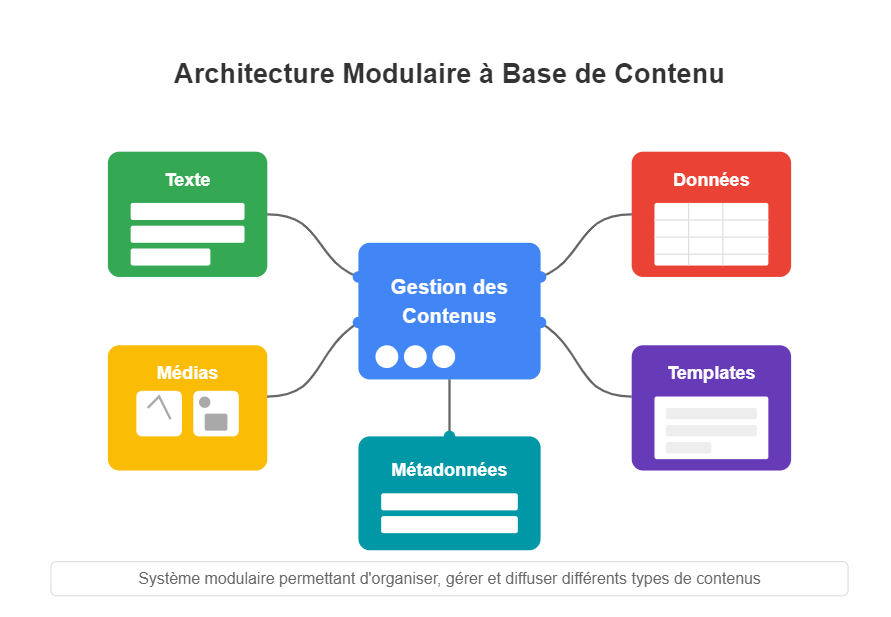
Architecture Modulaire à Base de Contenu
L'Architecture Modulaire à Base de Contenu (ou "Content-Driven Modular Architecture") représente une approche moderne et flexible pour concevoir des sites web et des applications. Cette méthodologie place le contenu au centre du processus de développement, en le séparant strictement de la présentation.
Mots-clés: développement, architecture, contentdriven, méthodologie, applications
Principes fondamentaux
Cette architecture repose sur plusieurs principes clés qui la rendent particulièrement efficace pour les sites riches en contenu comme les portfolios et les blogs :
Mots-clés: architecture, portfolios, principes, plusieurs
Le contenu est stocké dans des fichiers indépendants (souvent au format Markdown) avec des métadonnées standardisées (frontmatter), complètement séparés du code HTML, CSS et JavaScript qui définit leur présentation. Cette séparation permet à chaque aspect d'évoluer indépendamment.
Mots-clés: standardisées, indépendance, présentation
Les sections et composants peuvent être facilement réutilisés, réorganisés ou recombinés pour créer de nouvelles pages ou expériences. Cette flexibilité permet d'assembler rapidement différentes vues à partir des mêmes éléments de base.
Mots-clés: expériences, réorganisation, flexibilité
Modifier un contenu n'exige pas de toucher au code HTML principal. Les rédacteurs de contenu peuvent se concentrer uniquement sur les fichiers Markdown pertinents, sans risquer d'altérer la structure ou le fonctionnement du site.
Mots-clés: fonctionnement, pertinents, concentrer, uniquement, rédacteurs
Ajouter une nouvelle section est aussi simple que de créer un nouveau fichier Markdown. Cette approche réduit considérablement la friction pour enrichir le site avec de nouveaux contenus.
Mots-clés: contenus
Implémentation pratique
Pour les composants simples, le Markdown pur suffit généralement. Cependant, pour les composants plus complexes comme les grilles de compétences, les cartes de services, ou les processus multi-étapes, l'HTML embarqué dans Markdown offre le meilleur compromis :
Cette approche hybride permet de préserver le rendu visuel des composants complexes tout en profitant pleinement de la modularité du système.
Mots-clés: multiétapes, compétences, composants, markdown, modularité, composants, complexes
Avantages à long terme
Au-delà des bénéfices immédiats, cette architecture offre des avantages substantiels sur le long terme :
- Transitions technologiques facilitées - Le contenu peut être conservé même si le framework ou la technologie de présentation change
- Versionning efficace - Les modifications de contenu sont clairement visibles dans les commits Git
- Possibilités de migration accrues - Le contenu peut être facilement exporté vers d'autres systèmes
- Optimisation du workflow - Les designers et développeurs peuvent travailler sur l'interface pendant que les rédacteurs créent le contenu
Cette architecture représente une évolution naturelle des systèmes de gestion de contenu traditionnels, offrant davantage de flexibilité tout en conservant une structure claire et organisée.
Mots-clés: architecture, flexibilité
1. Séparation du contenu et de la présentation
Le contenu est stocké dans des fichiers indépendants (souvent au format Markdown) avec des métadonnées standardisées (frontmatter), complètement séparés du code HTML, CSS et JavaScript qui définit leur présentation. Cette séparation permet à chaque aspect d'évoluer indépendamment.
Mots-clés: indépendance, standardisés, présentation
2. Composabilité
Les sections et composants peuvent être facilement réutilisés, réorganisés ou recombinés pour créer de nouvelles pages ou expériences. Cette flexibilité permet d'assembler rapidement différentes vues à partir des mêmes éléments de base.
Mots-clés: flexibilité
3. Maintenabilité
Modifier un contenu n'exige pas de toucher au code HTML principal. Les rédacteurs de contenu peuvent se concentrer uniquement sur les fichiers Markdown pertinents, sans risquer d'altérer la structure ou le fonctionnement du site.
Mots-clés: pertinents, rédacteurs
4. Évolutivité
Ajouter une nouvelle section est aussi simple que de créer un nouveau fichier Markdown. Cette approche réduit considérablement la friction pour enrichir le site avec de nouveaux contenus.
Mots-clés: enrichir, contenus
Retour en haut